
正则表达式是操作字符串的一种逻辑公式,他使用事先定义好的特殊字符和这些特殊字符所构成的一种组合。正则表达式规定一些特殊语法,用来表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式(Regular Expression)。
如上面所说,正则表达式有三部分组成:字符类、数量限定符、位置限定符。下面详细举例说明。
1、字符类
. 匹配任意一个字符,比如下图所示food. 可以匹配fooda foodabcd
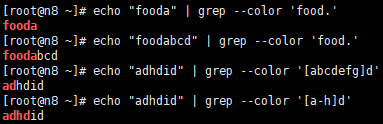
[ ] 匹配中括号中的任意一个字符,- 表示字符的范围,当然,你可以写任意字符。比如下图所示的[a-z]可以匹配a到z的所有字母

^ 可以匹配除了括号中的字符外的任意字符

[[:xxx:]]是grep工具预定义的一些命名字符,可以灵活使用

2、数量限定符
比如说,合法的邮箱地址,每一部分都可以有一个或者多个x字符,合法的IP地址每一部分可以有1-3个字符,等等
?紧跟在?前面的单元应匹配0次或者1次
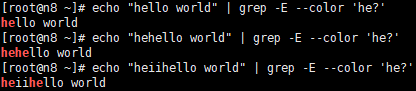
![]()
+紧跟在+前面的单元应匹配1次或者多次
![]()
*紧跟在*前面的单元应匹配0次或者多次
![]()
{N}紧跟在{N}前面的单元应精确匹配N次,例如[1-9][0-9]{2}匹配100-999的整数 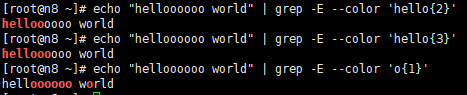

![]()
{N,}紧跟在它前面的单元应至少N次,例如[1-9][0-9]{2}匹配3位以上的整数
![]()
{,M}紧跟在它前面的单元应最多匹配M次,例如[0-9]{,2}表示最多匹配1次数字
![]()
{N,M}紧跟在它前面的单元匹配至少N次,最多M次,例如[0-9]{1,3}表示0-9数字至少匹配1次,最多匹配3次
![]()
3、位置 限定符
位置限定符(Anchor):描述各种字符类以及普通字符之间的位置关系,例如邮件地址分三部分,用普通字符@和.隔 开,IP地址分四部分,用.隔开,每一部分都可以用字符类和数量限定符描述。
^匹配行首的位置
$匹配行末的位置

\<匹配单词开头的位置
![]()
\>匹配单词词尾的位置
![]()
匹配某个单词
![]()
\b匹配单词的开头或者结尾的位置

\B匹配非单词开头或者结尾的位置

4、特殊字符
\转义字符,普通字符转为特殊字符,特殊字符转为普通字符。比如我们上面看到的\<就代表开头,因为<是个普通字符;而\.就是把特殊字符.转为普通字符的. 例如去匹配IP地址的时候就需要用到
![]()
() 将正则表达式的一部分括起来组成一个单元,可以对整个单元来使用数量限定符。例如可以用来表示IP地址。(下图的例子的意思我翻译一下,就是以0到9的数字出现1次到3次,也就是1到3位数嘛,并且后面跟着一个小数点.以这个为整体,用括号括起来,出现了3次。然后以0-9的3位数结尾的一组数字)
![]()
|连接2个子表达式,表示或的关系。例如使用^h|^H来匹配hello或者Hello
